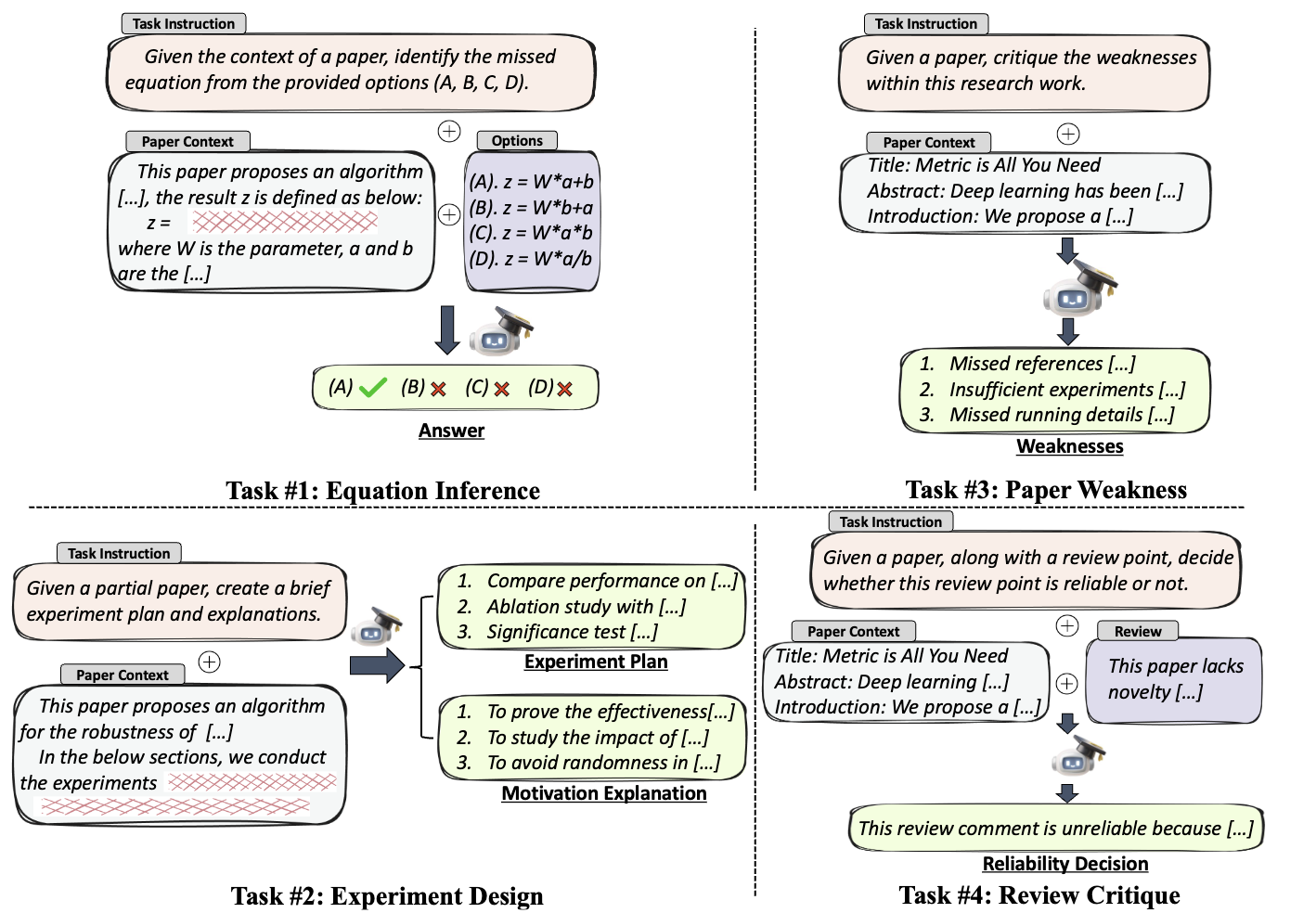
We introduce AAAR-1.0 ("1.0" denotes this work is a beginning of a series), a benchmark dataset designed to evaluate LLM performance in four fundamental, expertise-intensive research tasks, which most AI and Machine Learning researchers encounter daily:
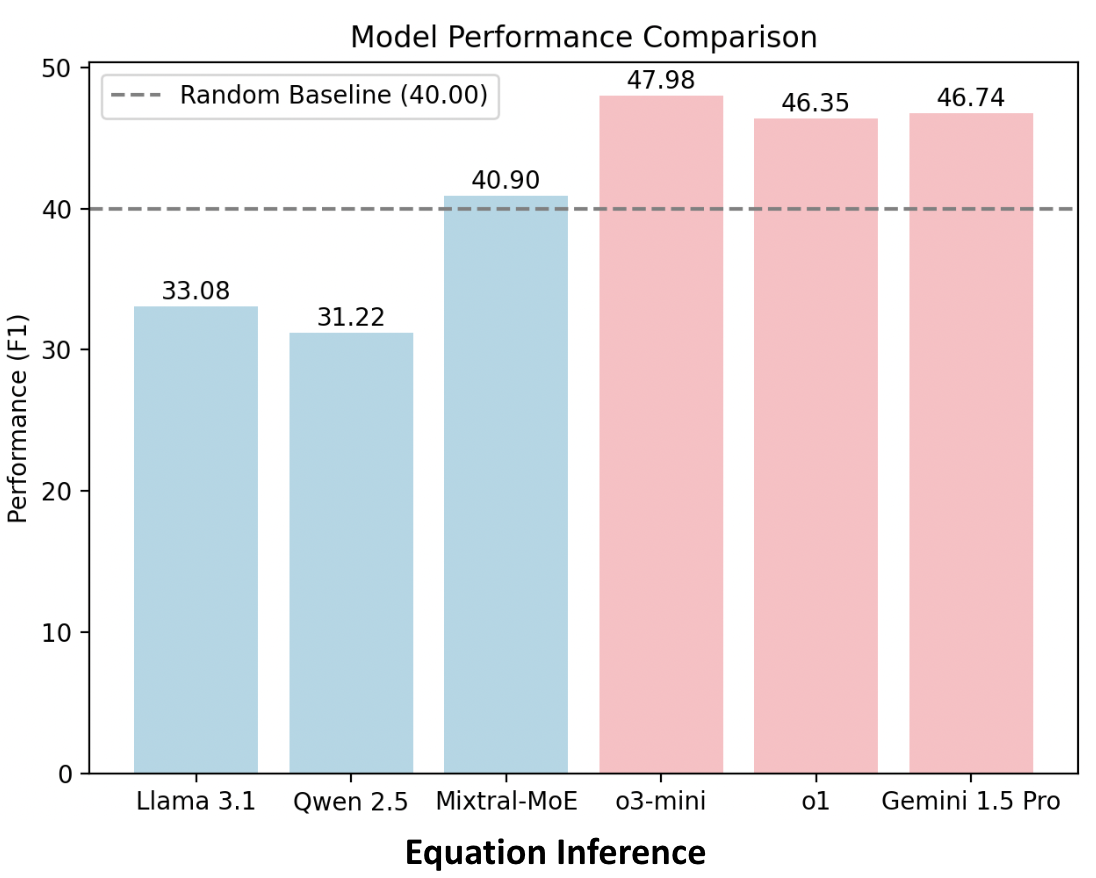
(i) EquationInference, assessing the correctness of equations based
on the contextual information in paper submissions;
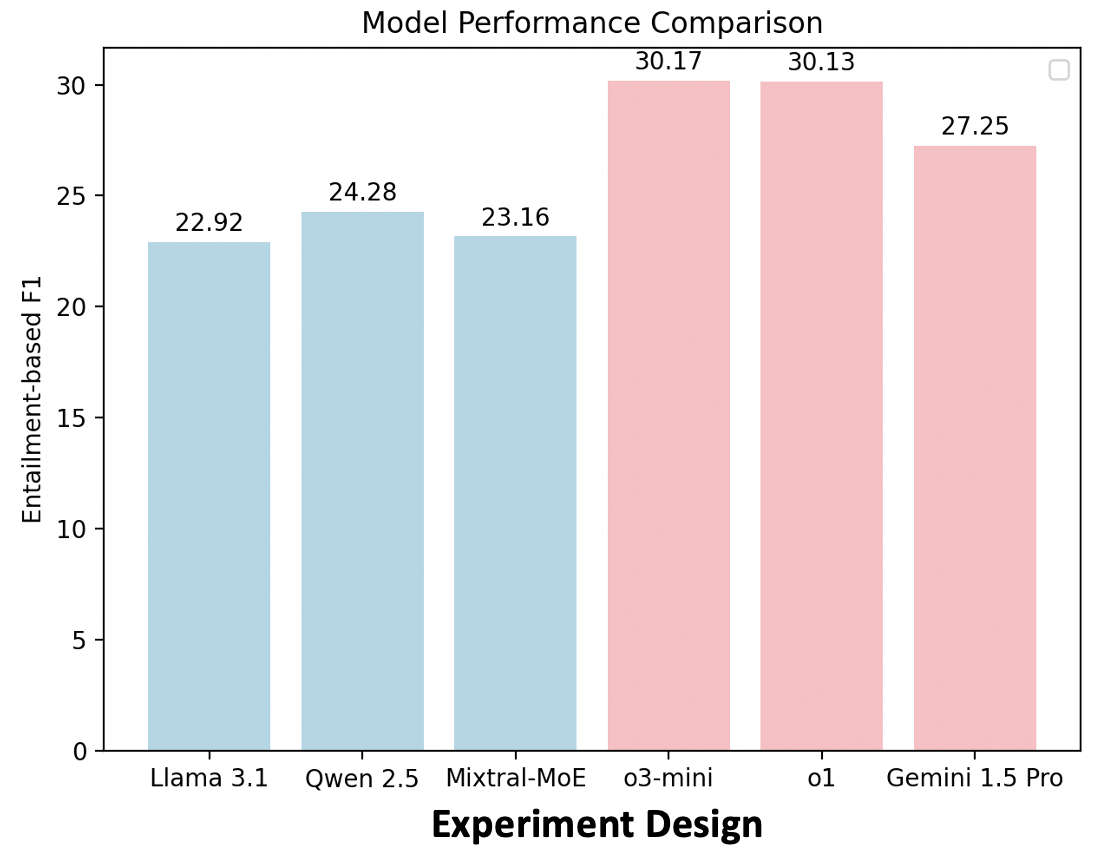
(ii) ExperimentDesign,
designing experiments to validate research ideas and solutions;
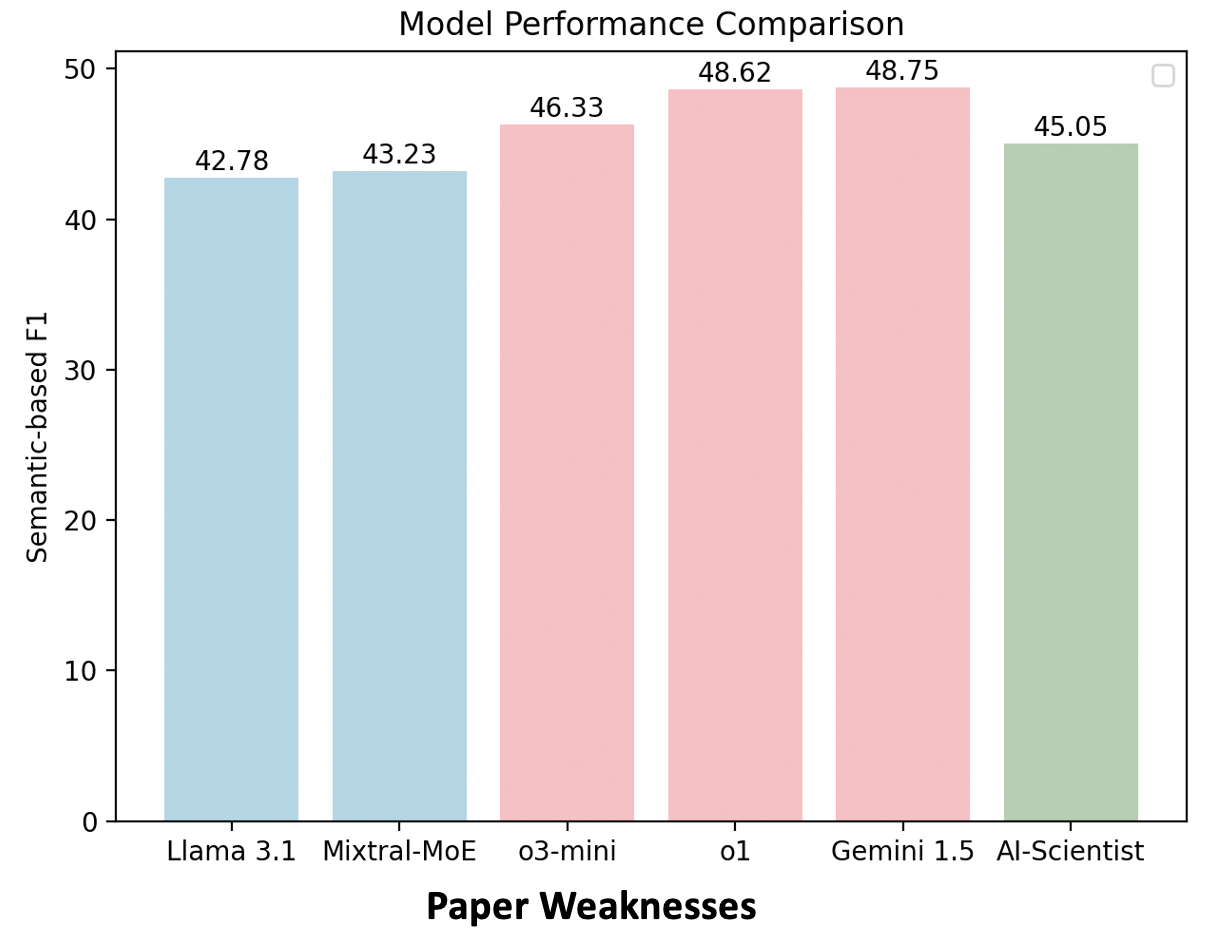
(iii) PaperWeakness, identifying weaknesses in paper submissions;
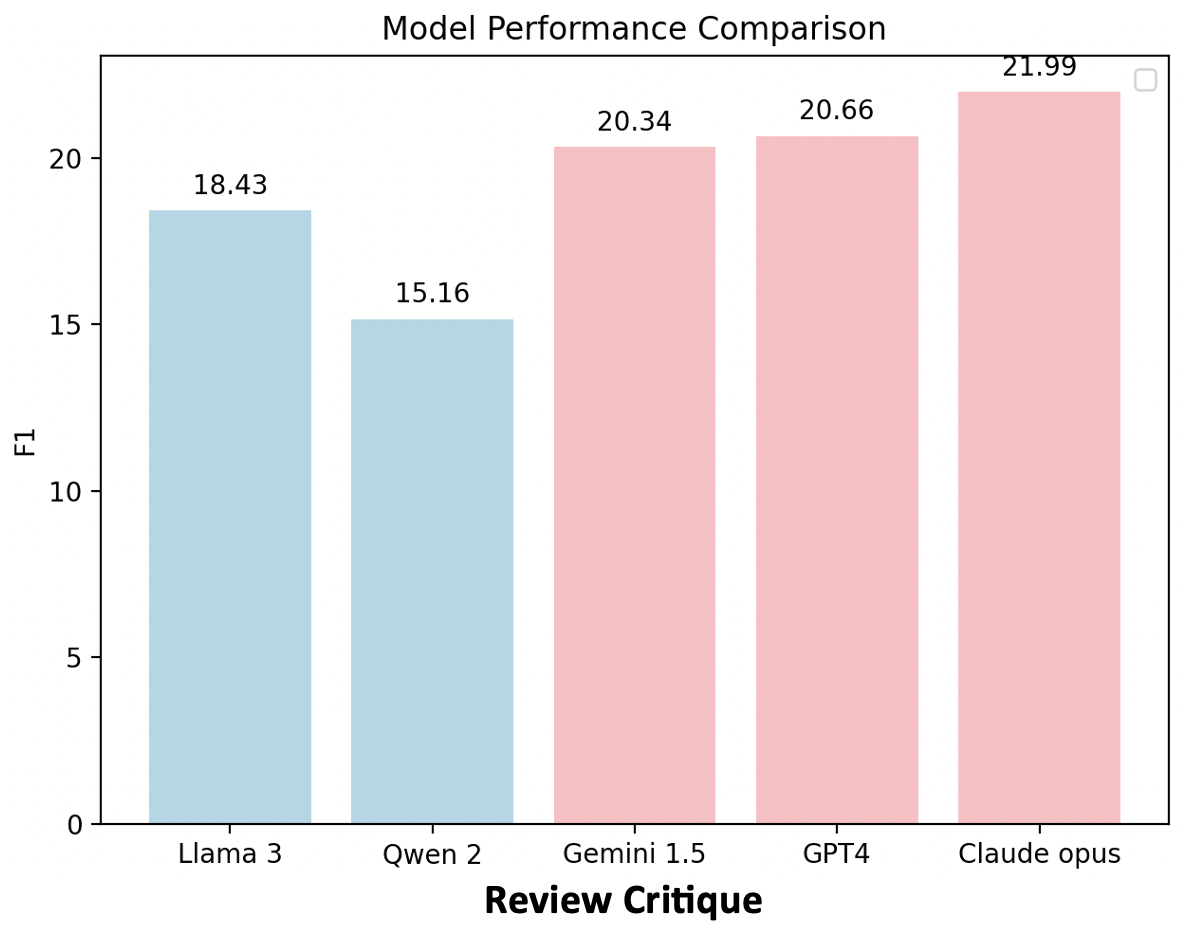
(iv) ReviewCritique,
identifying each segment in human reviews is deficient or not.
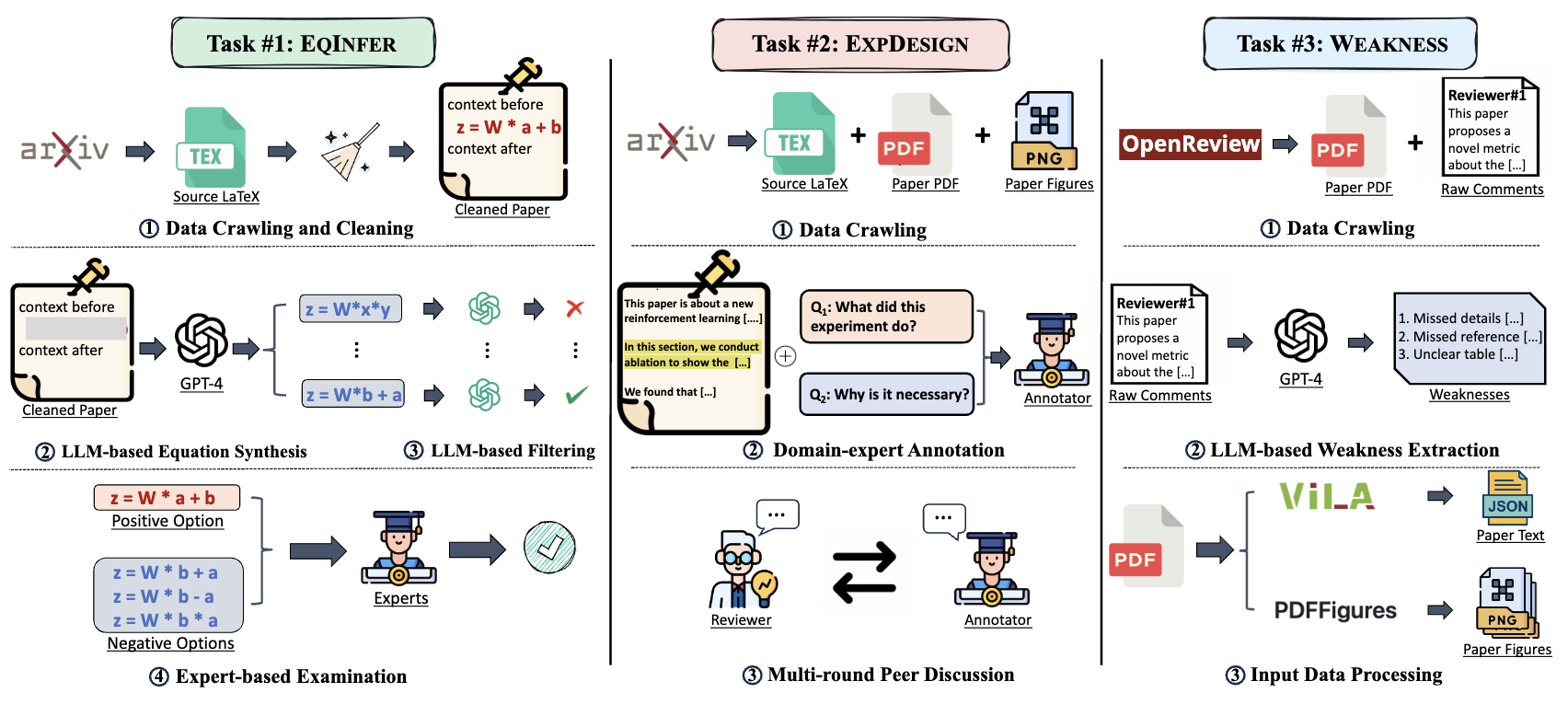
To ensure data quality, senior AI
researchers with extensive domain expertise perform data annotation for AAAR-1.0, followed by
rigorous multi-round data examination and filtering.
The proposd AAAR-1.0 becnhmark is:
(a) Challenging: All four tasks require models to possess strong
domain knowledge covering various cutting-edge research findings, as well as expert-level research
experience, to the extent that even humans need substantial research accumulation to tackle the tasks
we designed.
(b) Transparent & Quantitative: Tasks here are singular, stand-alone challenges (with clear input and output
expectations) rather than a complicated task chain. Benefiting from the proposed task-specific metrics, it provides a more transparent and quantitative assessment of the model's research outputs.
 AAAR-1.0: Assessing AI's Potential to Assist Research
AAAR-1.0: Assessing AI's Potential to Assist Research Pennsylvania State University;
2
Pennsylvania State University;
2 Netflix;
3
Netflix;
3  University of California, Davis;
University of California, Davis;
 University of Illinois Chicago;
5
University of Illinois Chicago;
5  Fudan University;
6
Fudan University;
6  Zhejiang University;
Zhejiang University;
 University of Alabama at Birmingham;
8
University of Alabama at Birmingham;
8  Ohio State University;
9
Ohio State University;
9  Salesforce Research
Salesforce Research